Tekstlaboratoriet i Aten: Konferansen LREC 2000
I månedsskiftet mai/juni i fjor var jeg
Tekstlaboratoriets utsendte medarbeider på den internasjonale
datalingvistikkonferansen LREC 2000, eller Second International Conference on
Language Resources and Evaluation, som var konferansens fulle navn.
Konferansen, som ble arrangert av The European Language Resources Association
(ELRA), fant sted i det storslåtte bygget Zappeion Megaron i sentrum av Aten.

Konferanselokalet: Zappeion Megaron
Konferansen varte i tre
dager, og hadde inntil fire parallelle foredragssesjoner eller seks parallelle
plakatsesjoner. Bidragene omhandlet en lang rekke datalingvistiske ressurser;
blant disse kan vi nevne talespråksdatabaser og elektroniske leksikon og
korpus, samt verktøy for morfologisk, syntaktisk og semantisk tagging av
korpus, informasjonsgjenfinning, termekstraksjon og talegjenkjenning og
-syntese. Som navnet på konferansen tilsier, tok også en del av bidragene for
seg metoder og verktøy som kan brukes i evalueringen av kvaliteten på de
datalingvistiske ressursene.
Tekstlaboratoriet bidro med en plakat der vi presenterte Oslo-korpuset av taggede norske tekster (se http://www.tekstlab.uio.no/norsk/bokmaal/), som ble fyldig omtalt i 1999-utgaven av Tekstlabbulletinen. I presentasjonen la vi spesiell vekt på det web-baserte grensesnittet vårt, og vi trakk blant annet fram et par spesielle typer av ord som man vanligvis ikke kan søke etter i andre korpus, men som vi har gjort søkbare i korpuset vårt, nemlig sammensetninger og unormerte ord. Plakaten tiltrakk seg mange interesserte tilskuere.
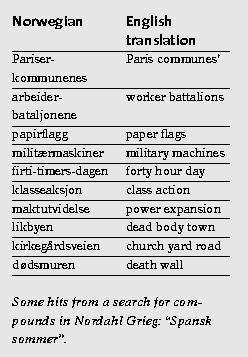

Utdrag fra Tekstlaboratoriets plakat:
sammensetninger og unormerte ord
Av andre norske bidrag kan vi nevne at Diana Santos holdt et inlegg sammen med Eckhard Bick der de beskrev hvordan de har gjort en rekke grammatisk taggede portugisiske korpus tilgjengelige over nettet, mens Knut Hofland fra HIT-senteret i Bergen presenterte et korpus av avistekster som blir automatisk utvidet med ca. 150 000 ord hver eneste dag.
Anders Nøklestad