Nomen Nescio
En automatisk
navnegjenkjenner for
norsk, svensk og dansk
Brita Andersen <personnavn> arbeider i parfymeriet Brita Andersen <firmanavn>.
Mannen hennes jobber i Volvo <firmanavn>. Han går fra Volvo <stedsnavn> til
huset sitt i Vestby <stedsnavn> på fem minutter. De så nettopp filmen Paris, Texas
<verksnavn>, og skal faktisk til Paris, Texas <stedsnavn> til sommeren.
Et nettverk innenfor NorFas Språkteknologiprogram
Et samarbeidsprosjekt mellom tre nordiske land
Janne Bondi Johannessen, prosjektleder, Universitetet i Oslo
http://spraakdata.gu.se/nn/
Nomen Nescio-prosjektet: Bakgrunn og aktiviteter
Janne Bondi Johannessen, prosjektleder,
Universitetet i Oslo
Mye flertydighet ved navn
Når vi søker etter informasjon på Internett, hender det ofte at vi i tillegg til informasjonen vi var ute etter, ofte også får informasjon om noe vi absolutt ikke er interessert i. Når jeg søker etter filmen Paris, Texas på Internett, får jeg masse informasjon om byen med samme navn: Official Paris Texas Homepage, Weather Underground: Paris, Texas Forecast, Paris, Texas - Dixie Youth Baseball. Faktisk får jeg bare ett treff blant de tretti første som gjelder filmen: Paris, Texas / Wim Wenders - The Official Site. Det hadde vært kjekt om søkesystemet hadde klart å sile ut de irrelevante treffene for meg.
Prosjektet
Vi ser at navn ofte er flertydige. Nomen Nescio-prosjektet har som mål å lage navnegjenkjennere som klarer å entydiggjøre navn av forskjellige kategorier for de tre språkene norsk, svensk og dansk. Mens det i utlandet har vært vanlig å prøve å skille kategoriene personnavn, stedsnavn og organisasjonsnavn fra hverandre, ønsker vi å utvide til kategorier som boknavn, sangnavn, navn på produkter, på hendelser osv.
Prosjektdeltagerne
Prosjektet involverer nå personer (fast ansatte og høyeregradsstudenter) fra Universitetet i Oslo, Universitetet i Bergen, Fast Search & Transfer, Göteborgs Universitet, Center for Sprogteknologi i København og Syddansk Universitet i Odense. Vi hadde vårt første felles seminar på Fefor Høifjellshotell i Norge i januar 2001. Det deltok 14 personer fra de tre deltagerlandene, samt tre gjesteforelesere fra Storbritannia (fra henholdsvis University of Sheffield og University of Edinburgh/Infogistics).

Noen fornøyde navnegjenkjenningsseminardeltagere:
Steven Finch, Anders Nøklestad, Kristin Hagen og Andra Björk Jonsdottir. (Foto:
Veronica Haderlein)
De 14 deltagerne var: Bo Pedersen, Yvonne Cederholm, Martin Gellerstam, Dimitris Kokkinakis, Torgny Rasmark, Pål Eriksen, Veronica Haderlein, Kristin Hagen, Botolv Helleland, Åsne Haaland, Janne Bondi Johannessen, Andra Björk Jonsdottir, Anders Nøklestad og Paul Meurer, pluss gjesteforeleserne Steven Finch, Diana Maynard og Andrei Mikheev.
Seminaret var meget vellykket. Deltagerne fikk anledning til å bli kjent med hverandre både faglig og mer personlig. Det var lagt opp til at alle deltagergruppene presenterte det de hadde av relevant programvare og navnelister, samt menneskelige ressurser, mens de utenlandske gjesteforeleserne redegjorde for navnegjenkjennere som var laget for engelsk, og metoder som var brukt der. Samtidig var det lagt inn lengre pauser midt på dagen, så vi fikk benyttet det lille dagslyset som var, til å gå på ski (eller til fots) i den flotte naturen. Mange hadde ski på beina for første gang. Kombinasjonen av faglig innhold og fysiske utskeielser med masse frisk og kald luft var veldig fin, og frister til gjentagelse. I mellomtiden arbeider de enkelte fagmiljøene videre med sine ting. Men vi kommer til å avholde flere seminarer utover de neste par årene, slik at de som arbeider på prosjektet kan vise hva de har oppnådd, og hvordan vi kan dra nytte av hverandres kunnskaper. Resultatene vil til slutt komme alle til gode, både i form av navnegjenkjennere som kan brukes i praktiske søkesystemer, men også som bidrag på konferanser nasjonalt på nordisk plan og helst også internasjonalt, samt artikler og ikke minst vitenskapelige avhandlinger.
Noen grunnproblemer
Ord og navn med stor bokstav
For at man i det hele tatt skal klare å skjelne mellom forskjellige navnekategorier, er det nødvendig å klare å skille ut automatisk det som er navn fra alle de andre ordene i en tekst. Det er ikke så enkelt som bare å ta ut de ordene som har stor forbokstav, for det første ordet i hver helsetning begynner jo med stor bokstav. Man kan heller ikke bare overse alle ord som står etter punktum, fordi enkelte punktumer hører til forkortelser. Setningene nedenfor viser noen eksempler på ord med stor bokstav i en tekst.
I dag snør det. Snø er kaldt. Bjørn liker ikke snø. Kvist er det mye av t.v. Berg og fjell er typisk norsk. T.v. står Berg.
Det er sju understrekede forekomster av ord med stor bokstav, men bare én er helt sikkert et navn fra et forenklet datamaskinsynspunkt, nemlig den siste, fordi det er det eneste ordet som begynner med stor bokstav samtidig som det ikke er første ordet i en setning eller første ordet etter punktum. Alle de andre tilfellene er i prinsippet flertydige, fordi de i tillegg til å være et fellesnavn, også kan være et egennavn (proprium), fordi de har stor bokstav. Nedenfor ser vi hvordan Oslo-Bergen-taggeren har tolket de understrekede ordene i sin første tilnærming, før den har prøvd å disambiguere eventuell flertydighet. Vi ser at det allerede er lagt inn en del føringer som gjør at mange av ordene med stor bokstav ikke engang foreslås som egennavn:
"<I>"
"I" subst prop
"I" det <romertall>
"i" prep
"<Snø>"
"snø" verb inf n pa4
"snø" verb imp n pa4
"snø" subst mask appell ub ent
"<Bjørn>"
"Bjørn" subst mask prop
"bjørn" subst mask appell ub ent
"<Kvist>"
"kvist" subst mask appell ub ent
"kviste" verb imp tr1
"<Berg>"
"Berg" subst prop
"<T.v.>"
"t.v." fork adv prep+subst @adv
"<Berg>"
"Berg" subst prop
Likevel er en del av ordene er flertydige. Når ikke alle er det, er det fordi det allerede på dette tidlige stadiumet i taggingen altså er lagt inn enkelte føringer på hva som må tolkes som navn og ikke. Den disambiguerende delen av taggingen tar seg av den videre behandlingen, og prøver å entydiggjøre de flertydighetene som finnes. Med ett unntak er nå ordene entydig analysert som enten egennavn eller fellesnavn:
"<I>"
"i" prep
"<Snø>"
"snø" subst mask appell ub ent
"<Bjørn>"
"Bjørn" subst mask prop
"bjørn" subst mask appell ub ent
"<Kvist>"
"kvist" subst mask appell ub ent
"<Berg>"
"Berg" subst prop
"<T.v.>"
"t.v." fork adv prep+subst @adv
"<Berg>"
"Berg" subst prop
I gjenkjenning av navn i tekst, slik vi har sett ovenfor, er det gjort en del arbeid både for norsk, for de andre språkene i prosjektet, og også for engelsk. Det er jo helt grunnleggende for all automatisk språkbehandling at man kan skille ut navn fra andre ord. Men navnene ovenfor har det til felles at de har stor forbokstav, og bare består av ett ord. Nedenfor skal vi se på noen vanskeligere tilfeller.
Ord og navn med liten bokstav
Men de skandinaviske språkene har også andre typer navn, nemlig navn som består av flere ord, og som kanskje grammatisk sett kan kalles fraser. Mens slike navn på engelsk har store forbokstaver i alle leddene, har de ikke nødvendigvis det på norsk, svensk og dansk. Nedenfor er en norsk tekst med eksempler på problematiske navn:
"Her er Gjerdrum likningskontor. Likningskontoret ligger rett ved Universitetet i Oslo. Rens På Timen er også i nærheten. Jeg liker Rens På Timen. Den norske lægeforening har mange medlemmer. Men Lægeforeningen er ikke så aktiv. Jeg synes Den norske lægeforening snart bør bli mer aktiv."
Nomen Nescio-deltager, forskeren Paul Meurer (UiB) og undertegnede (J.B. Johannessen, UiO) har utviklet en navneanalysator som klarer å kjenne igjen også slike problematiske navn, samt navn i problematisk kontekst, som de ovenfor. Noen slike problemnavn består av flere ledd, og noen av disse har bare én stor bokstav, mens andre har et par stykker. Andre er vanskelige fordi de har forskjellig form etter hvor de er nevnt (formen forkortes eller endres noe når navnet først er nevnt én gang). Atter andre er vanskelige fordi navnet er likt med ord som ikke er navn, og således ikke gjenkjennes uten videre når det kommer rett etter punktum. Vår navneanalysator kan testes på Internett, http://decentius.hit.uib.no:8005/cl/cgp/test.html:
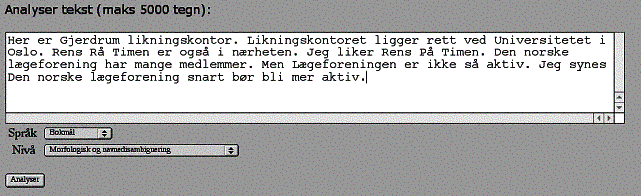
Nedenfor er resultatet av analysen av teksten over (bare navnene er tatt med):
"<Gjerdrum likningskontor>"
"Gjerdrum likningskontor" subst noeyt prop
"<Likningskontoret>"
"likningskontor" subst noeyt prop be ent
"<Universitetet i Oslo>"
"Universitetet i Oslo" subst prop
"<Rens Rå Timen>"
"Rens Rå Timen" subst prop
"<Rens På Timen>"
"Rens På Timen" subst prop
"<Den norske lægeforening>"
"Den norske lægeforening" subst prop
"<Lægeforeningen>"
"Lægeforeningen" subst prop
"<Den norske lægeforening>"
"Den norske lægeforening" subst prop
Vi skal ikke komme inn på metoden som ligger bak analysen, men vil nevne at det er viktig at navnene må forekomme i kontekst, og ikke bare stå alene i f.eks. en oppramsing eller tabell, for at analysen skal bli så bra som den har blitt. (Taggen "subst prop" står for "substantiv proprium", og betyr at navneanalysatoren har analysert riktig.)
Likevel må vi slå fast at en slik navneanalysator bare er første skritt på veien mot en navnegjenkjenner som jo skal kjenne igjen hva slags kategori de enkelte navnene tilhører, noe som altså er Nomen Nescio-prosjektets oppgave. På de neste sidene følger bidrag fra noen av de andre prosjektdeltagerne: Andra Björk Jonsdottir og Åsne Haaland fra Universitetet i Oslo, Dimitris Kokkinakis fra Göteborgs Universitet, Bo Pedersen fra Center for Sprogteknologi i Købehavn og gjesteforeleserne Diana Maynard med kolleger fra University of Sheffield, samt Andrei Mikheev fra University of Edinburgh og Infogistics Ltd..
Hovedoppgaveprosjekt: Titler og stedsnavn
Andra Björk Jonsdottir, hovedfagsstudent, Universitetet i Oslo
Innledning
Som student i norsk ved Universitet på Island ble jeg tilbudt et stipend for å studere nordisk ved Universitetet i Bergen i 1996. Med bakgrunn som en halvnorsk islending var det ikke bare faget som lokket, men også folket. Etter ett år i Bergen kom jeg til Oslo for å studere videre ved universitetet her. Med et stopp hos Norsk som andrespråk endte jeg på faget Språk, logikk og informasjon. Der har jeg funnet meg godt til rette og er nå godt i gang med hovedfaget mitt. Oppgaven jeg jobber med, inngår som en del av det NorFa-finansierte prosjektet Nomen Nescio (NN) - En automatisk navnegjenkjenner for norsk, svensk og dansk.
Jeg var heldig som kom inn i prosjektet da det var helt i startfasen. Jeg deltok blant annet på et seminar hvor alle prosjektdeltakerne var tilstede. I tillegg til at deltagerne ble kjent med hverandre og hver gruppe la fram sine tanker om hvordan vi skulle gå fram i arbeidet, fikk vi også besøk av tre gjesteforelesere fra De britiske øyer, Diana Maynard (universitetet i Sheffield) og Andrei Mikheev og Steven Finch fra universitetet i Edinburgh. Gjesteforeleserne hadde alle jobbet med navnegjenkjenningsprosjekter for engelsk, og det var inspirerende å se og høre hva de hadde fått til.
Navnegjenkjenning
Som et naturlig utgangspunkt i et prosjekt om navnegjenkjenning begynte vi med å bestemme oss for hvilke kategorier vi skulle jobbe med. For å kunne bestemme det, så vi på artikler om lignende prosjekter for engelsk og italiensk. Av de engelske navnegjenkjenningsprosjektene stammet de fleste fra Message Understanding Conferance (MUC) i 1996 og 1997. Der opererte man med tre kategorier; personnavn, stedsnavn og organisasjonsnavn, i tillegg til at datoer, prosenter og lignende ble trukket ut. Oppdragene for MUC ble gitt av det amerikanske forsvarsdepartementet, hvilket til en viss grad forklarer hvorfor akkurat disse tre kategoriene ble vektlagt. Det amerikanske forsvarsdepartementet er nok mest interessert i å kunne trekke ut fakta om personer, steder og organisasjoner, og mindre interesserte i bøker, filmer og musikk. Vi mener at det for vårt prosjekt er behov for flere enn bare de tre kategoriene MUC opererte med. Årsaken til dette er at vi tar sikte på å kunne gjenkjenne navnekategorier på et generelt grunnlag, som for eksempel ved søk på Internett, hvor man i høyeste grad interesserer seg for nettopp bok-, musikk- og filmtitler, i tillegg til de tre kategoriene hos MUC. Vår kategorisering heller mer i retning av det navneforskere nå har begynt å se på. Navneforskere har først og fremst konsentrert seg om personnavn og stedsnavn, men nå i den senere tid har de også begynt å se nærmere på det de kaller ”andre navn”. Blant forslagene de har, er kategori for saksnavn (med navn på konkrete ting som ikke viser til personer, dyr, vekster eller steder), for hendings- og epokenavn og for navn på publikasjoner og kunstverk.
Vi har kommet fram til følgende fem kategorier: personnavn, stedsnavn, organisasjonsnavn, produktnavn og titler. I Botolv Hellelands artikkel ”Andre navn” får vi støtte for å legge til kategoriene produkt og tittel. Han snakker der om navn for varemerker, med eksempler som Mercedes, Levis, Radionette og Walkman. Denne kategorien vil også samsvare med gruppen saksnavn som tidligere er nevnt. Navn for kunstverk som skulpturer, malerier, filmer, bøker og blad, setter Helleland sammen i en gruppe, med eksempler som Air, Pikene på broen, Fjols til fjells, Det store spelet og Dagbladet. Sistnevnte gruppe stemmer godt overens med vår kategori for titler, mens den svenske navneforskeren Bengt Pamp har en lignende gruppe han kaller abstraktnavn.
Min oppgave innenfor prosjektet
Jeg kommer til å konsentrere meg om to av kategoriene vi har pekt ut. Kategoriene jeg har valgt, er stedsnavn og den vi har kalt tittel. Hvorvidt tittel er et passende navn for denne kategorien, kan diskuteres. Det er mulig at verksnavn hadde passet bedre, men foreløpig beholder jeg tittelnavnet. Eksempler på navn som er ment å tilhøre denne kategorien er boktitler, filmtitler, navn på noveller, essay, musikkstykker, aviser og kunstverk. Det kan imidlertid vise seg at for eksempel navn på aviser passer bedre i ting(produkt)kategorien enn i tittelkategorien. Dette forbeholdet gjelder også for andre navn i tittelkategorien. Jeg regner med at denne typen problemer vil løse seg etter hvert som arbeidet går videre. Det er akkurat denne typen problemstillinger som gjør denne oppgaven morsom. Det jeg jobber med for øyeblikket, er å forsøke å identifisere kontekster hvor navn fra disse kategoriene forekommer. Ut i fra de kontekstene vil jeg forsøke å generalisere og lage CG-regler (Constraint Grammar) som jeg kan bruke i Oslo-Bergen-taggeren hos Tekstlaboratoriet ved UiO. Med slike regler skal taggeren bli i stand til å tagge semantisk kategori på egennavn.
En annen del av hovedoppgaven min er å lage et testprogram med brukergrensesnitt mot Internett. En bruker skal kunne teste spesifiserte søk i et korpus som allerede er tagget med både morfosyntaktiske tagger og de semantiske taggene for egennavn. For dette prosjektet blir det også nødvendig å lage et korrektkorpus med navnekategorier på plass.
Doktorgradsprosjekt: Anvendelse av statistiske
metoder i utviklingen av en automatisk navnegjenkjenner
Åsne Haaland, doktorgradsstudent, Universitetet i Oslo
1. Bakgrunn
Jeg er vit.ass. ved Tekstlaboratoriet, UiO, og skal ta doktorgraden samme sted. Planlagt start er i januar 2002 og arbeidstittel er: Anvendelse av statistiske metoder i utviklingen av en automatisk navnegjenkjenner. Jeg ble ansatt for å drive med statistikk. Jeg synes det er veldig spennende å skulle skifte felt, og å skulle begynne på noe helt nytt.
Fra før har jeg hovedfag i tysk
(moderne språk) og drøye to års matematikkstudier fra Universitetet i Oslo. Jeg
har alltid likt både språk og matematikk. At det er et overlapp mellom
matematikk, logikk og semantikk, har jeg vært klar over veldig lenge, men at
det var altuelt å bruke statistikk i forbindelse med lingvistikk, visste jeg
ikke. Etter at jeg kom i kontakt med Janne Bondi Johannessen, har jeg tatt et
par kurs i statistikk ved Matematisk institutt. Jeg hadde sterke fordommer mot
statistikk på forhånd, men statistikk er faktisk utrolig spennende! Det
følgende er tatt fra prosjektbeskrivelsen min.
2. Innledning
Ordklassetaggeren utviklet av Tekstlaboratoriet ved UiO finner navn i en tekst. Navnegjenkjenneren skal altså ikke ytterligere analysere hva som utgjør et navn, men bare bestemme hva slags navn det her dreier seg om: person-, firma- eller stedsnavn. Vi vil benytte metoden beskrevet i Mikheev, Moens og Grover (1999) og Mikheev, Grover og Moens (1998) til å utvikle en navnegjenkjenner for norsk. Metoden, som kombinerer navnelister, kontekstregler og statistisk metode, ga en svært god navnegjenkjenner for engelsk. Vi tror at en tilsvarende blandingsmetode i egenskap av å være en blandingsmetode vil gi den beste navnegjenkjenneren for norsk. Mitt doktorgradsprosjekt er å utvikle to forskjellige rent statistiske navnegjenkjennere samt den statistiske komponenten i blandingsmetoden. Jeg skal også benytte statistikk til å sammenligne forskjellige systemers prestasjonsnivåer.
3. Statistisk metode
En metode i naturlig-språk-prosessering (NLP) kalles ”statistisk” hvis den inneholder begrepet sannsynlighet eller beslektede begreper som entropi og informasjon. De statistiske metodene har tre ulike funksjoner: trening/læring (acquisition), anvendelse (application) og evaluering (evaluation). Acquisition (læring) brukes synonymt med maskinlæring. Navnegjenkjenning er en stokastisk prosess, dvs. at et isolert navn ikke nødvendigvis bare kan tilhøre en navnekategori, men derimot flere med forskjellig sannsynlighet: Navnene har en sannsynlighetsfordeling. Sannsynlighetsfordelingen må estimeres ettersom vi aldri kan få vite den virkelige sannsynlighetsfordelingen. Maskinlæring betyr at systemet ikke trenger å få kunnskap i form av håndskrevne regler, men estimerer sannsynligheter på grunnlag av et treningskorpus, eventuelt også ved hjelp av informasjon i leksikon eller, som her, navnelister. Initiering er nødvendig når treningskorpuset er utagget. Treningskorpuset er som regel forhåndstagget, men trenger altså ikke å være det. De estimerte sannsynlighetene lagres i en struktur. Anvendelse (application) er her utføringen av navnegjenkjenning på ukjent tekst: De estimerte sannsynlighetene brukes til å beregne sannsynlighetene for at det aktuelle navnet tilhører de forskjellige kategoriene, og den mest sannsynlige kategorien velges. Lærings- og utføringsfunksjonene lar seg riktignok ikke alltid skille fra hverandre, dvs. en metode kan ha begge disse funksjonene. Den tredje typen statistikk, evaluerende statistikk, benyttes til å evaluere prestasjonsnivået til forskjellige systemer, her navnegjenkjennere.
Når en statistisk metode erstatter håndskrevne regler, så er dette opplagt en svært kostnadseffektiv metode, og dette er hovedmotivasjonen for å bruke statistiske metoder i NLP. Tekstlaboratoriets erfaring fra utviklingen av en ordklassetagger illustrerer gevinsten ved å bruke statistikk: Mens det tok fire måneder å utvikle en rent statistisk tagger, krevde den ikke-statistiske taggeren med ca. 1000 Constraint Grammar-regler flere årsverk. Førstnevnte oppnådde en nøyaktighet på 95,9 %, mens sistnevnte oppnådde recall (funnrate) på 99,2 % og en presisjon på 96,8%.
3.1. Trening og anvendelse av
statistiske modeller
Vi tror at statistiske metoder vil kunne gi gode resultater for en navnegjenkjenner for de nordiske språkene. Mikheev et al (1999) og Bikel et al (1997) har benyttet statistiske metoder for navnegjenkjennere for henholdsvis engelsk (Mikheev et al) og for engelsk og spansk. De var begge blant de aller beste på MUC-konferansene, hovedarenaen for navnegjenkjenningsforskning internasjonalt. Bikel et als (1997) rent statistiske navnegjenkjenner benytter Markov-modeller, mens maksimum-entropi-modeller utgjør den statistiske komponenten i Mikheevs et als blandingsmetode. Jeg vil utvikle en navnegjenkjenner utelukkende basert på Markov-modeller og en annen basert på maksimum-entropi-modeller, og varianter av disse. Her nøyer jeg meg med bare å beskrive Markov-modeller.
Markov-modell
En Markov-modell beskriver en stokastisk prosess. Modellen består av et endelig antall tilstander, ved tagging utgjør taggene tilstandene. Startsannsynlighetene angir sannsynlighetene for at prosessen begynner i de forskjellige tilstandene, mens ettrinns-overgangssannsynlighetene angir sannsynligheten for at prosessen går fra en bestemt tilstand til en annen i løpet av et trinn. Overgangssannsynligheten avhenger bare av nå-tilstanden, og ikke av veien til denne tilstanden eller fremtidig oppførsel utover neste trinn (bigrammodell) og de er stasjonære, dvs. uavhengige av når overgangen skjer. Hvis modellen er synlig, kan vi til enhver tid kan se hvilken tilstand (her tagg) systemet befinner seg i. Dette er ikke tilfelle hvis Markov-modellen er skjult.
Trening på et forhåndstagget korpus gir som regel et bedre resultat, enn trening på et utagget korpus. Når treningskorpuset er forhåndstagget benyttes en synlig Markov-modell til treningen. Sannsynlighetsfordelingen estimeres vha. de relative frekvensene i treningskorpuset. Baum-Welch-algoritmen gir alternative, men antageligvis dårligere estimater.
Til taggingen benyttes derimot en skjult Markov-modell. At Markov-modellen er skjult, betyr at vi ikke har mulighet til å oppdage hvilke tilstander prosessen faktisk går gjennom. Ved overgangen fra en tilstand til en annen har vi derimot en (synlig) emisjon (her ord), som riktignok som regel ikke er entydig, men som tar flere former med forskjellige sannsynligheter. Disse kalles emisjonssannsynlighetene. Når teksten skal tagges, er nettopp ordstrengen synlig. Vi ønsker å bestemme hvilke tilstander prosessen mest sannsynlig har gått gjennom, gitt ordstrengen. I stedet for å se på hvert ord for seg og å bestemme den mest sannsynlige taggen tilhørende dette ordet, ser man på strenger av ord. Fordi de største enkeltordssannsynlighetene kan resultere i en svært usannsynlig tilstandsrekke, bestemmes den rekken av tilstander som med høyest sannsynlighet gir den observerte ordstrengen. Viterbi-algoritmen finner denne tilstandsrekken.
3.2. Evaluerende statistikk
Deskriptiv statistikk, dvs. presisjon og funnrate (precision and recall), skal benyttes til å måle forskjellige systemers prestasjonsnivå. Statistikk skal så benyttes til å nå en konklusjon om hvilke metoder som gir den beste navnegjenkjenneren: Jeg skal benytte teknikker for hypotesetesting og utregning av konfidensintervaller til å vurdere om forskjellige systemers verdier for precision og recall er signifikant forskjellige eller ikke. Det er internasjonalt økende forskningsaktivitet på meningsfylte mål for systemers prestasjonsnivå og måter å sammenligne disse på.
Namnigenkänning på svenska
Dimitrios Kokkinakis, Språkdata, Göteborg University
1 Inledning
Namnigenkänning är
en särskild utmaning på grund av de svårigheter och tvetydigheter som kan
uppstå vid igenkänning och kategorisering eller klassificering av namn, dvs
bestämma om ett namn refererar till en person, en plats eller en
organisation/företag. Namnet ”Victoria” t.ex. kan klassificeras
som bl.a.:
·
personnamn
(e.g. kronprinsessan Victoria)
·
idrottsplats
(e.g. OS-arenan "Victoria")
·
teaternamn
(e.g. film på Victoria)
·
namn på ett
kafé (e.g. Café Victoria)
·
teaterpjäs
(e.g. sextimmarsdrama Victoria)
·
symaskin
(e.g. symaskinen Singer Victoria)
Att korrekt
kunna känna igen egennamn och kategorisera olika namnvarianter är en svår men
viktig deluppgift i många datorlingvistiska tillämpningar, som t.ex.
informationsextrahering. Egennamn skiljer sig från andra ord i och med att de
inte finns med i de flesta ordböcker och det sättet som ett namn kan variera
(t.ex. stavning). Namnet ”John Fitzgerald Kennedy” kan påträffas i texter med
variantformerna:
·
J.F.K.
·
JFK
·
J.F.Kennedy
· Kennedy
· Kennedy, J.F.
· Kennedy, John Fitzgerald
Även ett
lexikon som täcker egennamn blir snabbt otillräckligt på grund av att nya namn
ständigt skapas eller lånas i språket.
2 Bakgrund och Metod
Hur man identifierar ett egennamn är inte
självklart, språkspecifika detaljerade förslag i uppgiftsbeskrivningen har
tagits fram i de s.k. MUC konferenserna (Message Understanding Conferances),
dessa var dock anpassade till de specifika teman som dessa konferenser handlade
om; t.ex. raketuppskjutning. Enligt MUCs specifikationer ingår i
namnigenkänningsuppgiften att identifiera och korrekt kategorisera: personer (PERSON), olika typer av organisationer
(ORGANIZATION), olika typer av
ortnamn (LOCATION), men också
information om icke-namnkaraktär, t.ex. datum- och tidsuttryck (DATE, TIME). Namn på produkter,
händelser av historiskt eller kulturellt intresse, namn på kometer, planeter,
fartyg, böcker, osv. behandlades däremot inte i det sammanhanget. MUCs
specifikationer finns på: http://cs.nyu.edu/cs/faculty/grishman/NEtask20.book_1.html.
En bra utgångspunkt i igenkänningsarbete är att använda en kombination av
namnlistor, kontextuell information samt skrivkonventioner (t.ex. många
egennamn i svenska inleds med en versal som är en viktig ledtråd i
igenkänningen). Alla dessa källor är dock problematiska. Versaler är till
exempel inte alltid en säker ledtråd, i kontexten ”Ett fotografi med titeln
Galna turister visar en gatumarknad i Brasilien” är ”Galna turister visar en
gatumarknad i Brasilien” ett namn där versaler inte spelar en avgörande roll
för klassificeringen av delsträngen.Våra metoder har än så länge varit att
identifiera och kategorisera namn mha kontextuell information (se http://spraakdata.gu.se/svedk/ne.html).
2.1
Exempel
Personnamn: vi har skapat listor med titelled som
vi kombinerar med textsträngar som följer eller föregår dessa och som har
ortografiska kännetecken (ord som börjar med versal). T.ex. ”herr X”, ”chefen X”, ”President X”. Listor
med typiska verb där ett personnamn ofta följer eller föregår verbet: t.ex. ”sa
X”, ”erkände X”, ”X erkände”.
Organisationsnamn: på samma sätt har
vi skapat regler som känner igen organisationsnamn, oftast mha ledtrådsord som
t.ex. ”AB”, ”Bank”, ”Ltd”, ”Industri”, ”Stiftelsen”, ”Inc.” osv.
Ortsnamn: vi använder typiska prepositioner, verb och suffix samt
ledtrådsord i kontexten för att känna igen ortnamn (länder, städer, byar,
flygplatser osv.); t.ex. ”ligger i X”,
”ön X”, ”staden X” och avledningssuffix som ”xxxbukten”,
”xxxstaden”, ” xxxborg”, ” xxxland”.
2.2
Exempel på taggad text
Bild 1 visar en
exempeltext, Bild 2 visar samma text där alla namn (enligt MUC) har markerats
med färg (svårt att urskilja i svartvitt) och Bild 3 visar uppmärkningen av
samma färgmarkeringar mha s.k. taggar (etiketter som beskriver vad för slags
namn eller entitet det handlar om).
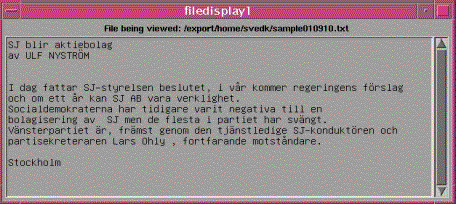
Bild 1
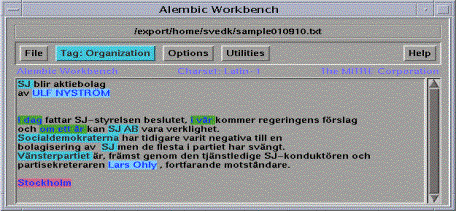
Bild 2
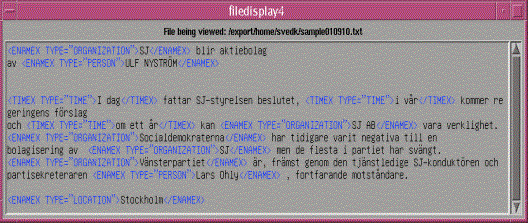
Bild 3
3 Slutsatser
I
namnigenkänningsarbete för svenska är det relativt enkelt att identifiera en
sträng som betecknar ett namn, men oerhört svårt att kategorisera den.
Användning av kontextuell information och skrivandet av kontextbaserade specifika
regler för vissa typer av namn är ett sätt att lösa problemet. Inom ”Nomen
Nescio”-projektet kommer vi att undersöka och
utveckla en plattform av kunskap och verktyg för namnigenkänning för svenska
och undersöka vikten av namnlistor och kontext i igenkänningsarbetet.
Automatisk navnegenkendelse ved hjælp af ordklasser
Bo Pedersen, Center for Sprogteknologi
En af de mest veludviklede metoder indenfor sprogteknologien er den automatiske genkendelse af ordklasser i en tekst. Der findes værktøjer som i op imod 97% af tilfældene automatisk kan sætte korrekt ordklasse på hver enkelt ord i en dansk sætning. Tag f.eks. en lille sætning som “Peter får en is”. En sådan sætning er let at analysere da de fleste af ordene kun kan betyde en ting:
Peter/E får/U en/K is/N
Ordet “Peter” er et egennavn og kan ikke være andet. Det samme gælder for “en” som kun kan være et kendeord og “is” som kun kan være et navneord.[1] Ordet “får” derimod kunne sagtens have været et navneord. Men pga. af den sammenhæng ordet indgår i er det klart for os at der er tale om et udsagnsord. Det er også klart for vores computerprogram som ved at sekvensen E-U-K-N er mere sandsynlig end E-N-K-N.
Computerprogrammet er “trænet” på en tekstsamling med 250.000 ord som et forskerteam har sat korrekte ordklasser på. Det er herefter testet på en tekstsamling med 28.000 ord som det aldrig har set før og her gætter det 96,5% af ordklasserne korrekt.[2]
Da programmet er trænet med ordklassen egennavn og derfor også kan genkende denne klasse er det oplagt at det også kan bruges til den mere specifikke opgave at genkende navne i tekster. Dette er dog ikke helt problemfrit da mængden af navne i en tekst er større end det som vi i tekstsamlingen har kategoriseret som egennavne. Tag f.eks. navnet “Det kongelige Teater” som i tekstsamlingen analyseres som “Det/S kongelige/T Teater/N” (Stedord, tillægsord, navneord).
Det er også et problem at programmet faktisk er noget svagere til at genkende ordklassen egennavn i forhold til andre ordklasser. Fejlprocenten på egennavne er således helt oppe på 22%.
Programmet bør med andre ord forbedres på dette punkt hvis det seriøst skal bruges til navnegenkendelse. Hvis det viser sig ikke at være muligt at forbedre programmet på dette punkt kunne man omvendt sige at programmet kunne drage nytte af en bedre genkendelse af egennavne.
Lad os se på hvad programmet faktisk gør når det møder en ny tekst.
Programmet laver to gennemløb af teksten. Et første, hvor den ved hjælp af en ordbog og nogle leksikalske regler (opbygget under træningen) tildeler ordklasser til de enkelte ord uafhængigt hvilke ord der er til højre og venstre. Under andet gennemløb ændres ordklasserne i forhold til hvilke ord der står omkring det pågældende ord – igen ved hjælp af regler der er opbygget under træningen af programmet.
Tidligt i første gennemløb “snyder” programmet en smule ved at tildele alle ukendte ord ordklassen N (navneord) med mindre de starter med et stort bogstav, og hvis det er tilfældet tildeles ordet i stedet ordklassen E (egennavn).
Herefter begynder programmet at bruge de leksikalske regler det har lært under træningen. Reglerne er sorteret efter hvor ofte de har været korrekte på træningssættet og derfor anvendes de vigtigste regler først. Herunder gives et par eksempler på de vigtigste regler vedrørende egennavne:
“Hvis et egennavn ender på -et så ret det til et navnord”
“Hvis et ord ender på –‘s så ret det til et egennavn i ejefald”
Det er ret let at finde undtagelser til disse regler, men de er jo heller ikke regler i traditionel forstand – de laver jo kun midlertidige tildelinger af ordklasser som sidenhen kan ændres af andre leksikalske regler eller i andet gennemløb af regler der vedrører ordstilling. Dette ses meget tydeligt på nogle af reglerne som i sprogvidenskabelig forstand er det rene nonsens, men som pga. statistiske omstændigheder er ganske effektive, f.eks. følgende regel:
“Hvis et navneord i ejefald ender på –as så ret det til et egennavn i ejefald”
En hurtig optælling i ordbogen viser faktisk at 111 ud af 263 der ender på –as faktisk er egennavne i ejefald så reglen er ikke det rene nonsens. Igen skal man huske på at reglen ikke fungerer alene, men at der bliver udført regler senere som korrigerer for nogle af fejltagelserne. Faktisk er denne regel selv en slags korrektion på en noget grovkornet regel der er blevet udført tidligere som kalder alt der ender på –s for ejefald.
I andet gennemløb korrigeres der ved hjælp af et tilsvarende regelsæt på sætningsniveau. Eksempler på sådanne regler er:
“Hvis et egennavn efterfølges af navneord i ejefald så ret sidstnævnte til et egennavn i ejefald”
Givet en del-sætning som eksempelvis “Andrew/E MacGee's/NE vodka/N” så vil denne blive ændret til “Andrew/E MacGee's/EE vodka/N” (Hvor NE = Navneord i ejefald og EE = Egennavn i ejefald)
Reglen virker overbevisende, men isoleret set kan den dog fejle på sætninger som “Jeg gav Peter dagens is”
En anden vigtig regel er:
“Hvis et navneord i ejefald efterfølges af et egennavn så ret sidstnævnte til et navneord”
Givet et eksempel som “Fodboldens/NE helte/E” så bliver det ændret til “Fodboldens/NE helte/N”
Igen findes der modeksempler selvom disse formentlig er i mindretal: “Fodboldens Mekka”.
Der findes også en håndfuld vigtige regler som vedrører sætningsgrænserne, herunder eksempelvis:
“Starter sætningen med et navneord efterfulgt af et egennavn så ret navneordet til et egennavn”
“Slutter sætningen med et egennavn så ret det til et navneord”
“Slutter sætningen med et egennavn fulgt af et navneord så ret navnordet til et egennavn”
Igen sandsynlige og effektive regler med masser af undtagelser. I bunden af regelhierakiet har vi regler som f.eks. “Et navnord der efterfølges af ordet ‘tog’ ændres til et egennavn” og “Et egennavn efter ordet ‘et’ rettes til et navneord” og “Et egennavn efter ordet ‘Dansk’ rettes til et navnord”.
Sidstnævnte regel er lidt ironisk da ordet ‘Dansk’ jo højst sandsynlig er et led i en navnekonstruktion og illustrerer meget godt at programmet ikke kigger efter navne der er sammensat af flere ord.
Men bortset fra det syntes programmet at have et potentiale som navnegenkender. Problemet med sammensatte navne kunne muligvis løses ved at udvide egennavnklassen så denne omfatter mere end navneordsformen og ejefaldsformen. Dette vil kræve en ny runde, hvor tekstsamlingerne manuelt bliver analyseret med disse, og en ny træningsrunde, hvor programmet forsøger at lære disse former at kende.
Mere realistisk er det nok at forsøge at udvide regelsættet manuelt med regler som fordrer navnegenkendelse (på bekostning af den almindelige genkendelse), og kombinere dette med et par efterbehandligsrutiner. Der er trods alt en del at gå efter når teksten først er tagget. Mange faste former træder klart frem, f.eks. “Det kongelige Teater”, hvor sekvensen af ordklasser kombineret med informationen om at første og sidste ord skrives med stort giver os et hint om at vi har med et navn at gøre (ordene “kongelige” og “teater” giver også et statistisk hint om at vi har med et navn at gøre).
En strategi kunne være at søge i den oprindelige tekstsamling efter ord med stort startbogstav og så forsøge at kategorisere alle konstruktionerne i forhold til hvordan de opfører sig ordklassemæssigt og derpå formulere regler i programmets regelsæt.
Named Entity
Recognition at Sheffield University
Diana Maynard, Hamish Cunningham, Rob Gaizauskas,
Dept of Computer Science, University of Sheffield, UK
Introduction
The robust handling of proper names is essential for many different applications within Natural Language Processing (NLP). In particular, Named Entity recognition (NE) is one of the key components of Information Extraction (IE). The University of Sheffield's NLP Group has a long history of work in this area, and has been developing IE systems within the GATE architecture since 1996, when the group first took part in the Message Understanding Competitions (MUC) organized by DARPA. The NLP research group has been involved in a wide variety of Information Extraction (IE) projects in the last decade, many of which revolve around the GATE architecture and the LaSIE information extraction system developed within it. GATE and its core information extraction components have been used in several EC Fourth and Fifth Framework projects and has been installed at hundreds of sites world-wide.
Named Entity Recognition Projects
The University of Sheffield has built a variety of different applications using the same core NE technology. This technology consists of tools for part-of-speech tagging, parsing, grammars, etc. and, at its heart, a set of gazetteer lists and a hand-coded rule-based grammar. It demonstrates the usefulness of having a good basic approach to named entity recognition, and, even more importantly perhaps, the significance of a general-purpose architecture for language processing such as GATE, which enables the development of such resources and tools.
The core IE system, LaSIE was originally developed for participation in the MUC 6 evaluation, where it achieved a very creditable score of 92% combined precision and recall for named entity recognition, and also participated in the tasks of co-reference, summarization, template element filling, and scenario template filling.
From LaSIE, a number of other systems have been developed, such as the PASTA system [Humphreys et al, 2000], in which the basic NE system has been adapted to identify terminology from the field of molecular biology. This project used IE techniques to create a database of protein active site data to support protein structure analysis.
The MUMIS project (MUltiMedia Indexing and Searching environment) applies IE technology to multimedia, multilingual video indexing in the football domain. Again, this uses named entity recognition at the heart of its approach. The University of Sheffield is supplying information extraction tools to support this joint research involving partners from Germany, Sweden, Bulgaria and the Netherlands.
Current research on Named Entity Recognition
Current research at the University of Sheffield is focusing on robust and adaptable approaches to named entity recognition. In particular, the MUSE system (Multi-Source Entity Finder) aims to recognize named entities from a variety of textual sources involving different domains, genre, media and text type. It also aims to work on degraded text such as automatically transcribed spoken messages, and text produced by optical character recognition (OCR). This is a challenging task because, in the case of the former, lack of punctuation and capitalization makes it much harder to recognize and characterize proper nouns correctly; and in the case of the latter, incorrect words compound the problem, particularly where traditional techniques such as list lookup and part-of-speech taggers are used, since these rely on correct words.
The MUC evaluations in the last decade paved the way for huge advances in the field of Information Extraction and particularly NE. Even though only a handful of institutions (all US-based) were directly funded to take part, these evaluations gradually led to the participation of sites from all over the world, and new initiatives sprang up to investigate different methods for NE recognition, from purely statistical approaches and learning approaches to hand-coded rule-based approaches. However, one of the ensuing problems was that because the tasks were very domain-specific, the development of multi-purpose systems that could easily be adapted for different tasks was inhibited. Even within the area of IE, most systems that participated in the competition were not designed to handle all the different sub-tasks. The GATE system is unique in that it enabled the development of tools to participate in all 5 of the MUC subtasks. Regarding NE itself, however, even the LaSIE system developed within GATE was lacking, because it required a substantial amount of effort to adapt its named entity component to a new domain, let alone a new application.
The MUSE system attempts to tackle these kinds of problems head-on, by using a set of interchangeable processing resources, and an automatic switching mechanism to select the most suitable resource for the task at hand. For example, different text types and domains may have different formatting procedures, or may not follow strict punctuation or capitalization standards, all of which can be harnessed by the system for optimal processing.
The Future isn't English
Although the majority of work in Named Entity Recognition has been for English texts, clearly there is a growing need for such systems to operate on other languages, and in particular, on non-European languages. To be truly generic, language engineering tools cannot be limited to specific languages or writing systems. One major hurdle to the development of such systems is that they must be able to handle non-Western scripts, such as those of Chinese, Japanese, Russian and Indic languages. GATE has been developed to provide full Unicode support for diverse languages and their scripts , and can handle font mapping to allow corpora to be standardised around Unicode. Our NE systems can now operate successfully on these scripts, and a prototype NE recogniser has been written for Bengali, as part of the EMILLE project on South Asian languages.
Conclusions
We have presented here a brief summary of some of the ongoing work at Sheffield in Information Extraction and Named Entity Recognition, within the framework of a more global perspective. It is evident that although there have been many recent advances in Named Entity Recognition, the needs of the community are expanding in two main directions: the requirements for more generic architectures and systems that can easily be adapted to different applications and environments, and the need for processing of other languages apart from English, and in particular, non-European languages.
Named Entity Recognition - Task Profile
Andrei Mikheev, Infogistics Ltd and University of Edinburgh
Named Entity Recognition Task Definition
•
Named Entity Recognition (NER) in its strict sense
involves identification of proper
names in the texts and their classification
into a set of predefined categories of interest.
•
Three universally accepted categories: person, location and organization.
•
Preprocessing
tasks - recognition of date/time expressions,
telephone/email, measures (percent, money, weight, length, height..)
•
domain specific named entity -- names of drugs (Methanol), medical
conditions (Coronary Heart Disease), names of laws, names of ships,
bibliographic references etc.,
NER Task Definition Loopholes
Intuitively category definitions are quite clear. “Gray
area” of definitions due to metonymy of names:
Company vs artefact
it produces
shares of MTV vs watching MTV
Boeing spokesman vs. ordering another Boeing
Organization vs Location (physical area it occupies)
airports,
restaurants, schools, etc., mostly are used as locations
she met him at O'Hare airport vs O'Hare
airport authorities
List - Lookup Approach
System that
recognizes only those entities which are stored in its lists (gazetteer,
name database, name lists, etc.).
General Lists
-- 5,000 locations + 33,000 organizations + 27,000 people
Learned Lists
-- MUC’7 training corpus -- 100 articles from New York Times (NYT)
Test
-- MUC’7 formal test sample of 100 articles from NYT
Learned General Combined
P R P
R P
R
organization
49 75 3
51 50 72
person 26 92 31 81 47 85
location 76 93 74 94 86 90 <== NOT BAD
(P=precision, R=Recall)
Strong points
-- simple, fast, language independent, easy to retarget;
Weak points
-- collection and maintenance of lists; cannot deal with name variants; cannot
resolve ambiguity (e.g. Washington);
Shallow Parsing Approach (1)
Internal Evidence
- Names often have internal structure. Some components of this structure can be
listed in lists and others can be easily guessed
Person:
ChristianName + CapWord John Bush
ChristianName + CapLetter + “.”
+ CapWord John W. Bush
Tile (Dr., Mr., )
+ CapWord Dr. Johns
Location:
CapWord + {City,
Forest, Center}
Sherwood Forest
CapWord +
{Street, Str, Blvd., Ave.} Bucchanan
Street
Number + “,” +
CapWord[1-2]+ CityName 24, Mouse Trap,
London
Organization:
CapWord[1-] +
{Inc., Ltd., Plc.}
Infogistics Ltd.
CapWord[1-] +
{Bank, Airlines, Air} North American Airlines
Shallow Parsing Approach (2)
External Evidence
- names often are used in very
predictive local contexts.
Person:
CapWord, “a” +
ADJ* + Profession Bush, a keen gardener
CapWord, NUMBER, Bush, 56,
CapWord + “himself” Bush himself
Location:
“to the” +
COMPASS+ “of” +CapWord to the south of Kosovo
CapWord, “is a” +
ADJ* + GeoWord Kharkov is a large city
“based in” + CapWord based in Lubertsi
Organization:
Profession {of,
for} CapWord[1-] director
of Happy Surf
shares of
CapWord[1-]
shares of Infogistics
CapWord[1-], a
subsidiary of Happy Surf, a subsidiary of
Difficulties in Shallow Parsing Approach
Ambiguously capitalized words (first word in sentence)
[All American
Bank] vs. All [State Police]
Semantic Ambiguity:
“John F. Kennedy”
and “O’Hare” -- airports (locations)
Philip
Morris
-- company (organization)
Structural ambiguity
Internal conjunction vs conjunction of two
names
[Cable and
Wireless] vs [Microsoft] and [Oingo Co.]
Internal vs External prepositions “of”,
“for”, “at”
[Center for
Demographic Studies] vs. message from
[NY Hospital] for [John Smith]
Internal vs External possessive ending “’s”
[America's
Utility Fund’] vs. [Ruppert Murdoch]'s
[B Sky B]
Adjacent names:
manager
for [Hong Kong] [Vassili Tkatchenko]
Capitalized Word
challenge
(Proper Name or Common
Word)
Document Centered Approach (DCA)
•
Important words are typically used in a document more
than once and in different contexts.
•
Some of these contexts create very ambiguous
situations but some don't.
•
Ambiguous words and phrases are usually unambiguously introduced at least once in
the text unless they are part of common knowledge presupposed to be known by
the readers.
•
The essence of the DCA is to scan the entire document
for the contexts where the words in question are used unambiguously.
DCA to Proper Names
Main Challenge -- single words which are not
covered by contextual patterns. No internal and external evidence to
disambiguate.
Important words are typically used in a document more than
once and in different contexts. Ambiguous words and phrases are usually
unambiguously introduced at least once in the text unless they are part of
common knowledge presupposed to be known by the readers.
For example, people
are often referred to by their surnames (e.g., ``Black'') but usually introduced
at least once in the text either with their first name (``John Black'') or with
their title/profession affiliation (``Mr. Black'', ) and it is only when their
names are common knowledge that they don't need an introduction ( e.g.,
``Castro'', ``Gorbachev'').
Suggestion:
first to look for unambiguous usages and then assign these words in ambiguous
positions. This is like on-line learning from documents under processing.
Cascaded Hybrid Architecture
We developed an architecture which uses rules for describing
internal structure and contextual evidence applying patterns which include list
lookup (semantic class) and POS tagging (syntactic class) information:
PERSON = CapWord +
“is a” + ADJ* + Profession
Bush is a keen gardener
After a named entity expression has been recognized and
classified we add words from this expression to corresponding lists which are
then applied to the processing of this document.
Bush ==> FOUND_SURNAME
PERSON = FOUND_ SURNAME
We process document in two phases sure-fire phase and general
phase. Each of these phases includes application
of rules and then population of the lists.
Sure-fire rule application -- at this stage we apply structural
and context rules which guarantee not
to produce errors. Information from lists is treated
as “likely” rather then definite. Names of locations listed in the gazetteer
are tagged only if they are used in specific contexts indicating locations.
Organization names with internal ambiguity (conjunction, preposition,
posessive) are not tagged at this stage.
Person names are tagged only when internal and contextual patterns
predict the same category for an instance of named entity.
Result: tagged only a small proportion of named entities (30-40%) but with
high precision (98%).
Internal lists are populated with document
specific words. All
Named Entities matched by the sure-fire rules are collected. From each named entity the system generates
all possible partial orderings preserving words order:
Rocket Systems
Development Co:
Systems Development, Rocket Systems Development, Rocket Systems,
Rocket Development Co. Rocket Development
These partial names matched in the document and assigned if
there is no contradiction. If a word or
phrase is generated from expressions of different class this assignment is
blocked.
Another variant to use a Maximum Entropy model trained for
such assignment.
Result : Recall
70-80% (+40%) Precision 97% (-1%)
The sure-fire stage and the partial match after it usually
identify and assign “difficult” cases, e.g. when a person name stands for a
company name.
At general match
stage we apply all the rest of rules. Now all ambiguous
conjunctions are treated as internal because otherwise we
would match separate company
names at the sure-fire and partial match phases.
Result: Recall:
85-90% (+20%) Precision 96% (-1%)

The very first seminar at the Nomen
Nescio- Named Entity Recognizer project
took part at beautiful Fefor Høifjellshotell
(Photo: Veronica Haderlein)